HTTP
HTTP (HyperText Transfer Protocol),即超文本运输协议,是实现网络通信的一种规范。
传输的数据并不是计算机底层中的二进制包,而是完整的、有意义的数据,如 HTML 文件、图片文件、查询结果等超文本,能够被上层应用识别。
在实际应用中,HTTP常被用于在Web浏览器和网站服务器之间传递信息,以明文方式发送内容,不提供任何方式的数据加密。
HTTP 的特点
- 支持客户/服务器模式。
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于 HTTP 协议简单,使得 HTTP 服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP 允许传输任意类型的数据对象。正在传输的类型由 Content-Type 加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:HTTP 协议无法根据之前的状态进行本次的请求处理。
HTTP 发展史
- HTTP/0.9:只有一个命令 GET;没有 HEADER 等描述数据的信息;服务器发送完毕,就关闭 TCP 连接
- HTTP/1.0:增加了很多的命令(POST、PUT、HEAD...);增加 status code 和 header;多字符集支持、多部分发送、权限、缓存等
- HTTP/1.1:持久连接( TCP 连接保持,让多个 HTTP 连接使用);pipeline (服务端对于多个 HTTP 只能串行处理,后面响应较快的请求会被阻塞);增加 host 和其他一些命令(同一个物理服务器下允许多种服务 node、java...)
- HTTP/2:所有数据以二进制传输(数据帧);同一个连接里面发送多个请求不再需要按照顺序来;头信息压缩以及推送等提高效率的功能(推送:用户请求 HTML 的同时,把所需的 css、js 资源同时主动推送给客户端,无需等待 HTML 的解析,达到资源并行获取的效果)
HTTPS
HTTP + SSL / TLS = HTTPS
HTTP 传递信息是以明文的形式发送内容,这并不安全。而 HTTPS 出现正是为了解决 HTTP 不安全的特性。
SSL (Secure Sockets Layer 安全套接字协议),及其继任者 TLS(Transport Layer Security 传输层安全)是为网络通信提供安全及数据完整性的一种安全协议。
实现
- 对称加密:采用协商的密钥对数据加密
- 非对称加密:实现身份认证和密钥协商
- 摘要算法:验证信息的完整性(hash函数、散列函数)
- 数字签名:身份验证(数字证书 => 摘要算法+服务器加密)
🌐 SSL/TLS的工作原理(opens new window)在新窗口打开
CA 数字证书
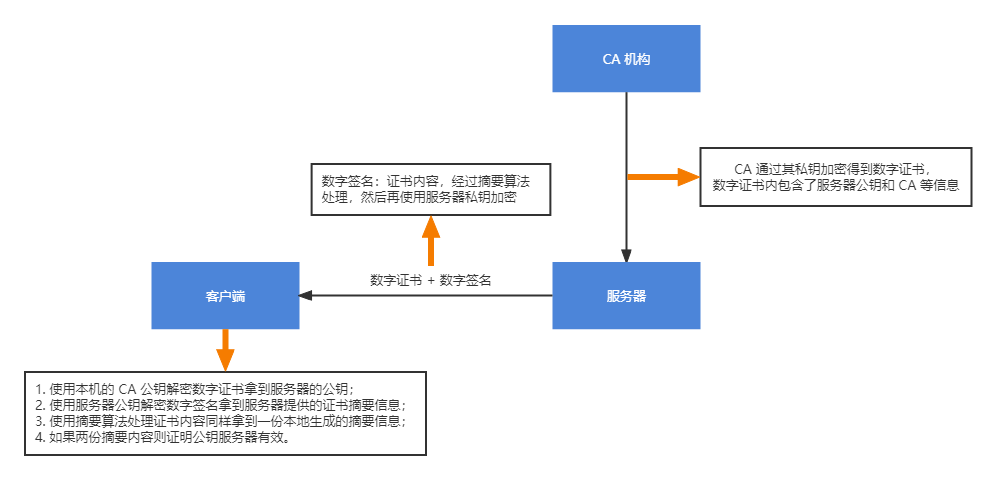 在建立 http 连接时,服务器不直接向客户停供公钥,而是发送包含公钥的数字证书以及通过摘要算法然后进行私钥加密的数字签名。 客户拿到数字签名之后,通过公钥解密数字签名拿到数字证书的摘要,然后使用相同的摘要算法处理数字证书,如果两份摘要是一致的,且数字证书是有效的,则证明该公钥是未被篡改的、完整的。
在建立 http 连接时,服务器不直接向客户停供公钥,而是发送包含公钥的数字证书以及通过摘要算法然后进行私钥加密的数字签名。 客户拿到数字签名之后,通过公钥解密数字签名拿到数字证书的摘要,然后使用相同的摘要算法处理数字证书,如果两份摘要是一致的,且数字证书是有效的,则证明该公钥是未被篡改的、完整的。
5 层网络协议模型
应用层(HTTP、FTP、TFTP、DNS、SMTP...):为应用软件提供了很多服务,构建于 TCP 协议之上,屏蔽网络传输的相关细节。
传输层(TCP、UDP):向用户提供可靠的端到端(End-to-End)服务,在网络层建立了双方的连接后,定义了两端如何去传输数据,传输数据的方式,数据的分包分片、组装等等实现。
传输层向高层屏蔽了下层数据通信的细节。
网络层(ARP、IP、ICMP...):为数据在节点之间传输创建逻辑链路(比如定义本机如何寻找访问服务器地址的逻辑关系)。
数据链路层:在通信的实体间建立数据链路连接(物理连接之后,需要软件服务来创建一个电路的连接,使双方能够传输数据 0/1。
物理层:定义物理设备如何传输数据。
TCP 的三次握手
TCP 与 UDP
- TCP 是面向连接的协议,建立连接3次握手、断开连接四次挥手,UDP是面向无连接,数据传输前后不连接连接,发送端只负责将数据发送到网络,接收端从消息队列读取。
- TCP 提供可靠的服务,传输过程采用流量控制、编号与确认、计时器等手段确保数据无差错,不丢失。UDP 则尽可能传递数据,但不保证传递交付给对方。
- TCP 面向字节流,将应用层报文看成一串无结构的字节流,分解为多个TCP报文段传输后,在目的站重新装配。UDP协议面向报文,不拆分应用层报文,只保留报文边界,一次发送一个报文,接收方去除报文首部后,原封不动将报文交给上层应用。
- TCP 只能点对点全双工通信。UDP 支持一对一、一对多、多对一和多对多的交互通信。
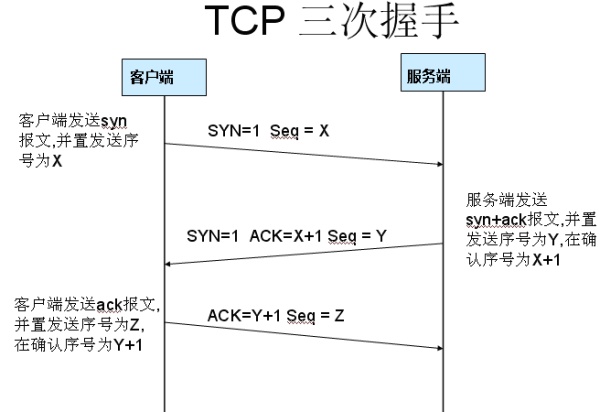
✅ 三次握手
主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备
第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c),此时客户端处于 SYN_SENT 状态
[SYN] Seq=0 Win=64240 Len=0 MSS=1460 WS=256 SACK_PERM=1(Seq = X)第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,为了确认客户端的 SYN,将客户端的 ISN+1作为ACK的值,此时服务器处于 SYN_RCVD 的状态
[SYN ACK] Seq=0 Ack=1 Win=14600 Len=0 MSS=1412 SACK_PERM=1 WS=128(ACK=X+1 Seq=Y)第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,值为服务器的ISN+1。此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接。
[ACK] Seq=1 Ack=1 Win=66304 Len=0(ACK=Y+1 Seq=Z)
URI、URL、URN
URI:
Universal Resource Identifier统一资源标志符。用来标识互联网上的信息资源,包括了 URL 和 URNURL:
Universal Resource Locator统一资源定位器,唯一地标识一个资源在 Internet 上的位置。不管用什么方法表示,只要能定位一个资源,就叫 URL。(<方案>:<方案描述部分>http://user:pass@host.com:80/path?query=string#hash<方案>://<用户名>:<密码>@<主机>:<端口>/<url路径>URN:
Universal Resource Name永久统一资源定位符。它命名资源但不指定如何定位资源,比如:只告诉你一个人的姓名,不告诉你这个人在哪。例如:telnet、mailto、news 和 isbn URI 等都是 URN。
URI 指的是一个资源,URL 用地址定位一个资源,URN 用名称定位一个资源
HTTP 报文
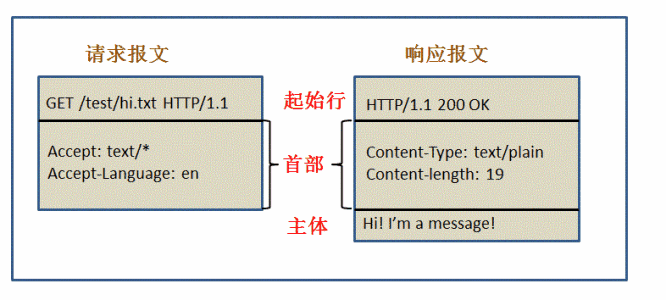
请求的起始行:method + path + version
响应的起始行:version + status code + status text
http 方法:用来定义对资源的操作;http code:定义服务器对请求的处理结果
header 与 body 之间有一个空行
curl 指令的简单应用
curl 它的功能非常强大,命令行参数多达几十种。如果熟练的话,完全可以取代 Postman 这一类的图形界面工具。
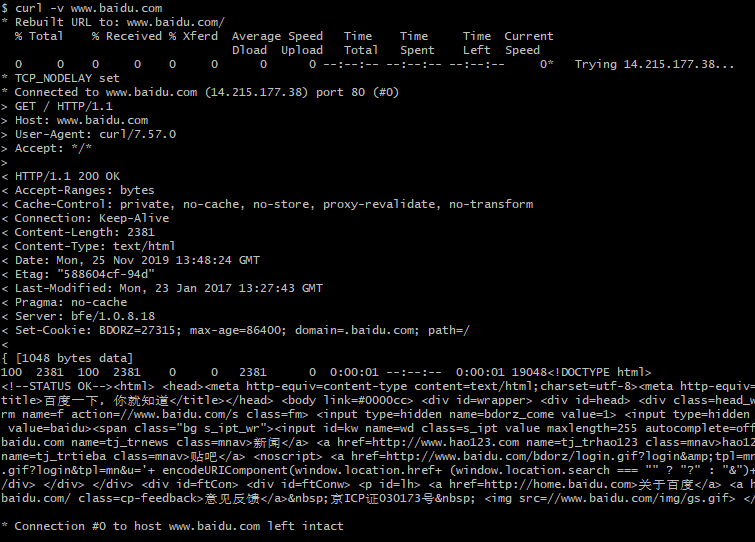
不带有任何参数时,curl 就是发出 GET 请求。
$ curl https://www.example.com
上面命令向www.example.com发出 GET 请求,服务器返回的内容会在命令行输出。
-v 参数输出通信的整个过程,用于调试。
$ curl -v https://www.example.com>
--trace参数也可以用于调试,还会输出原始的二进制数据。
$ curl --trace - https://www.example.com
跨域
Access-Control-Allow-Origin
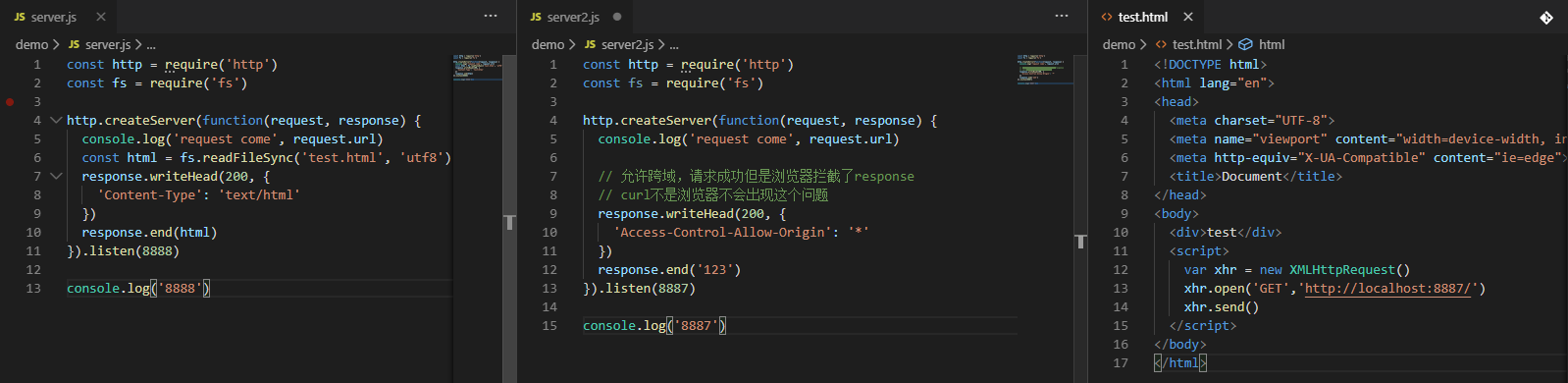
在 8888 端口下返回 test.html 文件,在 test 中访问 8887 端口
跨域会导致浏览器拦截 response:Access to XMLHttpRequest at 'http://localhost:8887/' from origin 'http://localhost:8888' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
response.writeHead(200, {
'Access-Control-Allow-Origin': '*',
});
2
3
* 表示允许任何服务都接受,可以设置特地域名
response.writeHead(200, {
'Access-Control-Allow-Origin': 'http://localhost:8888',
});
2
3
JSONP
原理:浏览器允许 link script 和 img 标签加载数据,不需要设置允许跨域 Access-Control-Allow-Origin
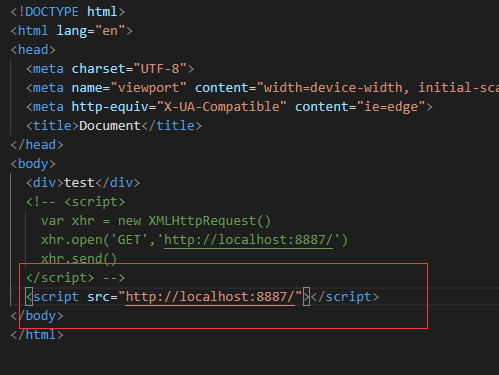
CORS 跨域限制及预请求校验
限制
保持 Access-Control-Allow-Origin 允许之下,仍然是有限制的(返回 200 但是浏览器不允许)
- 允许方法: GET、HEAD、POST
- 允许的
Content-Type:text/plain、multipart/form-data、application/x-www-form-urlencoded - 其他限制:请求头限制、XMLHttpRequestUpload 对象均没有注册任何事件监听器、请求中没有使用 ReadableStream 对象
fetch('http://localhost:8887/', {
method: 'POST',
headers: {
'X-Test-Cors': '123',
},
});
// X-Test-Cor 自定义的请求头默认不允许
2
3
4
5
6
7
预请求 OPTIONS
response.writeHead(200, {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': 'X-Test-Cors',
'Access-Control-Allow-Methods': 'POST,PUT,Delete',
'Access-Control-Max-Age': '1000', // 1000s 之内不再需要发送 OPTIONS 预请求
});
2
3
4
5
6
通过服务端设置允许的请求头来保证这个跨域请求的进行,在查看 Network 时会看到有两条请求记录:
- OPTIONS:验证服务端是否允许此请求头的跨域
- POST
Access-Control-Max-Age
表示跨域请求的参数事件内在第一次预请求之后的时间内不需要再发送 OPTIONS 预请求(second)
Cache-Control 缓存
这个请求头只是一个希望你按照的这个规则来,你可以不遵守
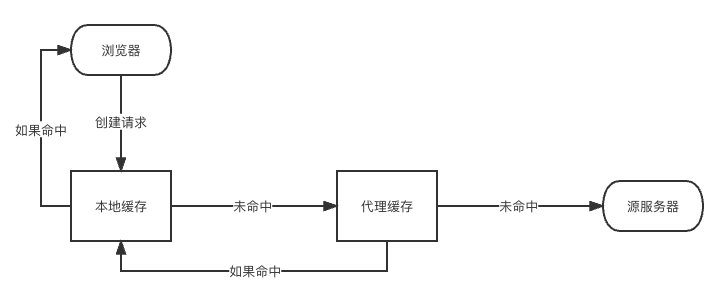
可缓存性
'Cache-Control': 'max-age=200, public'
- public: 代表 http 经过的任何地方,客户端、浏览器、包括代理的中间服务器都可以进行缓存
- private: 只有发起请求的浏览器可以进行和缓存
- no-cache: 可以缓存的,但是每次访问缓存之前需要发送一个请求验证是否可以使用缓存的数据
到期
max-age (s)
指这个缓存什么时候到期,之后需要重新发起请求而不能读取缓存的内容。
response.writeHeader(200, {
'Content-Type': 'text/javascript',
// 请求后的200s内再请求可使用缓存数据
'Cache-Control': 'max-age=200',
});
2
3
4
5
s-maxage(s)
在浏览器中会读取 max-age, 但是在代理服务器中如果同时存在 max-age 和 s-maxage, 会读取 s-maxage。
max-stale(s)
发起请求的一方主动带的一个请求头,即使 max-age 已经过期,超出 max-age 时间的响应消息如果还在 max-stale 有效期之内,还能读取缓存的内容,而不需要重新发起请求。
重新验证*
must-revalidate
缓存如果过期必须从原服务端发送请求验证这个缓存是否真的过期,来重新获取数据,而不能读取本地缓存
proxy-revalidate
在代理服务器中需要重新验证
其他
no-store
'Cache-Control': 'max-age=200000, no-store'
客户端和代理服务器都不可以使用缓存数据,必须重新发送请求。
no-transform
代理服务器不能改动数据,例如压缩等等操作
no-cache 资源验证
如果只是设置 'Cache-Control': 'max-age=200000',浏览器不需要通过服务端的验证即可读取缓存(Size:from memory)
Last-Modified
对比上次修改的时间,验证资源是否需要更新。配合 If-Modified-Since 或者 If-Unmodifiled-Since 使用。
服务端设置 Last-Modified,下次浏览器请求会带上 If-Modified-Since,以此判断资源是否修改过,然后确认要不要读取缓存的数据还是重新发起请求。
ETag / If-None-Match
数据签名,对比资源的签名判断是否使用缓存。
资源修改后就更新 Etag,配合例如对内容进行一个 hash 计算,判断两者是否一样,配合 If-Match 和 If-None-Match 使用。
这里的
max-age的时间虽然很长,浏览器可以缓存。但设置了no-cache,浏览器还是需要通过服务端的验证才能使用缓存
response.writeHeader(200, {
'Content-Type': 'text/javascript',
'Cache-Control': 'max-age=200000,no-cache', // no-cache
'Last-Modified': '123', // updated
'ETag': '777',
});
// Request Headers:
// If-Modified-Since: 123
// If-None-Match:777
const etag = request.headers['If-None-Match']
if (etag === '777') {
// 304 Not Modified 读取缓存数据
response.writeHeader(304, {
'Content-Type': 'text/javascript',
'Cache-Control': 'max-age=200000,no-cache', // no-cache
'Last-Modified': '123',
'ETag': '777',
});
response.end('')
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
当请求返回 304(Not-Modified)时,此时使用本地缓存的数据,在 respond 里面的内容实际上是缓存的数据
Chrome 可以 Disable cache,浏览器就不会发送缓存相关的请求头
Response Headers => ETag;Request Headers => If-None-Match
cookie 和 session
cookie
cookie
- node 里面通过 Set-Cookie 设置
- 下次同域请求的 head 里面会自动带上这个数据
- 键值对,可以设置多个 key=value
'Set-Cookie':'id=123'
'Set-Cookie':['id=123','abc=456]
- max-age 和 expires 设置过期时间
- Secure 只在 https 的时候发送
- HttpOnly 无法通过 document.cookie 访问
所以当 Response Headers 里有
Set-Cookie字段(一个或多个)的时候,浏览器就会把 cookie 写入到浏览器下次请求的时候 Requeset Headers 会有
Cookie字段带上浏览器的 cookie 到服务端
cookie 的过期时间是在浏览器关闭之后失效,在没有设置过期时间的情况下
- 过期之后下次请求 Request Headers 的 Cookie 便不会带上这个 key=value
- max-age 指有效时间是多长,expires 指到这个时间点过期。max-age 会方便一些。
// cookie 如果过期,浏览器请求就不会带上这个 cookie
response.writeHeader(200, {
'Content-Type': 'text/javascript',
'Set-Cookie': ['id=123;max-age=10','abc=456;HttpOnly'],
});
2
3
4
5
cookie domain
cookie 在当前域下写入在其他域是无法访问的
但是如果在 test.com 里面设置了 cookie ,二级域名下 a.test.com/b.test.com 都可以访问。
Response Headers:
'Set-Cookie': ['abc=456;domain=text.com', 'id=123']
session
cookie 不等于 session,session 的实现方式有很多种,cookie 只是其中一种。
例如通过对不同用户设置不同的唯一的 cookie 的 key=value 值,来定位用户的数据
🚀 只要能保证定位到用户的信息数据,那么它就是一种 session 的实现方案。那么通过请求头携带能够解析到用户信息的字段也算是 session 的一种实现。
HTTP 长连接
http 的创建过程中需要创建一个 TCP 连接,长连接可以保持 TCP 的连接不关闭,减少三次握手导致的开销。
chrome 下可以最多保持 6 个 TCP 的并发,那么 http 长连接可以在此 6 个 TCP 连接内传输
http 连接是否复用 tcp 连接由 Connection 声明。当然,在请求地址是同域的前提下
现代浏览器下和框架下一般都是长连接 Connection: keep-alive (close)
response.writeHeader(200, {
'Content-Type': '......',
// 每个http请求都要创建一个TCP连接
Connection: 'close',
});
2
3
4
5
HTTP2:信道复用,tcp 内可以并发 http 请求,不再是1.1里面可能阻塞的串行请求。
数据协商
Accept (客户端)
Accept:想要的数据类型Accept: */*Accept-Encoding:客户端接受的数据编码方式,限制服务端的数据压缩方法Accept-Encoding: gzip, deflate, br服务端使用 gzip 文件可以减少传输的网络带宽消耗,浏览器接收到后再进行解压缩。
Accept-Language:判断返回的语言Accept-Language: en,zh;q=0.9,zh-CN;q=0.8(q 越大表示权重越大 )User-Agent:表示系统和浏览器的一些相关的信息User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36
Content (服务端)
Content-Type
Content-Type:服务端返回的数据格式 (type/subtype)
// Response Headers,让浏览器不预测返回的数据类型
'X-Content-Type-Options': 'nosniff'
2
旧版本 IE 浏览器在响应数据未返回 Content-Type 的时候,会预测返回的数据类型进行处理,例如把文本当脚本处理,这可能导致安全信息被泄露。
现代浏览器基本上没这个问题了。
✅ 发送请求也可以带 Content-Type,有时候客户端需要告诉服务端发送的数据类型,让服务端进行处理。
✅ enctype
form 的 enctype 只能接受三种:application/x-www-form-urlencoded、multipart/form-data 和 text/plain
<form action="/form" method="POST" enctype="application/x-www-form-urlencoded">
<input name="name" type="text" />
<input name="password" type="password" />
<input type="submit" />
</form>
2
3
4
5
<form action="/form" method="POST" enctype="multipart/form-data">
<input name="name" type="text" />
<input name="password" type="password" />
<input type="file" name="file" />
<input type="submit" />
</form>
2
3
4
5
6
提示
GET 请求只支持 ASCII 字符集,因此,如果我们要发送更大字符集的内容,我们应使用 POST 请求。
✅ 默认情况下是 application/x-www-urlencoded,当表单使用 POST 请求时,数据会被以 x-www-urlencoded 方式编码到 Body 中来传送
✅ 而如果 GET 请求,则是附在 url 链接后面来发送(query)
✅ 如果要发送大量的二进制数据(non-ASCII),"application/x-www-form-urlencoded" 显然是低效的,因为它需要用 3 个字符来表示一个 non-ASCII 的字符。因此,这种情况下,应该使用 "multipart/form-data" 格式。
application/x-www-urlencoded
我们在通过 HTTP 向服务器发送 POST 请求提交数据,都是通过 form 表单形式提交的
application/x-www-form-urlencoded,意味着消息内容会经过 URL 格式编码,就像在 GET 请 求时 URL 里的 QueryString 那样,txt1=hello&txt2=world
<form method="post" action="http://w.sohu.com">
<input type="text" name="txt1" />
<input type="text" name="txt2" />
</form>
2
3
4
POST / HTTP/1.1
Content-Type:application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: w.sohu.com
Content-Length: 21
Connection: Keep-Alive
Cache-Control: no-cache
txt1=hello&txt2=world
2
3
4
5
6
7
8
9
对于普通的 HTML Form POST 请求,它会在头信息里使用 Content-Length 注明内容长度。 请求头信息每行一条,空行之后便是 Body,即“内容”(entity)。内容的格式是在头信息中的 Content-Type 指定的
multipart/form-data
multipart/form-data
文件不能作为字符串进行传输,应该以二进制进行传输。如果还是使用application/x-www-form-urlencoded拼接字符串的形式就无法把文件正常发送给服务端。
boundary 用来分割提交表单每项的每一个部分
<FORM method="POST" id="form" action="/form" enctype="multipart/form-data">
<INPUT type="text" name="city" value="Santa colo" />
<INPUT type="text" name="desc" />
<INPUT type="file" name="pic" />
</FORM>
2
3
4
5
var form = document.getElementById("form")
form.addEventListener('submit', function(e){
e.preventDefault()
var formData = new FormData(form)
fetch('/form', {
method: 'POST',
body: formData
})
})
2
3
4
5
6
7
8
9
POST /t2/upload.do HTTP/1.1
User-Agent: SOHUWapRebot
Accept-Language: zh-cn,zh;q=0.5
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Content-Length: 60408
Content-Type:multipart/form-data; boundary=ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Host: w.sohu.com
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data; name="city"
Santa colo
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="desc"
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="pic"; filename="photo.jpg"
Content-Type: application/octet-stream
Content-Transfer-Encoding: binary
... binary data of the jpg ...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC--
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 从上面的
multipart/form-data格式发送的请求的样式来看,它包含了多个 Parts,每个 Part 都包含头信息部分,Part 头信息中必须包含一个Content-Disposition头,其他的头信息则为可选项, 比如Content-Type等。- 当为文件类型的时候,会有 filename 等补充内容。
- 每个部分使用
--boundary分割开来,最后一行使用--boundary--结尾。
Redirect 重定向
临时跳转 302:将请求重定向到新的地址,指定
Location字段表示临时的新地址。永久跳转 301:永久定向到一个新的路由。
302 需要先到旧地址再到新地址,301 则让浏览器下次直接访问新地址
注意:301 会导致浏览器后续一直访问缓存数据,无法控制缓存
if (resquest.url === '/') {
response.writeHead(302, {
Location: '/new',
});
// redirect 就不需要返回内容了
response.end();
}
if (resquest.url === '/new') {
response.writeHead(200, {
'Content-Type': 'text/html',
});
response.end('<div>this is content</div>');
}
2
3
4
5
6
7
8
9
10
11
12
13
14
CSP
Content-security-Policy
内容安全策略:限制资源获取;报告资源获取越权
- 当网页中可能出现一些不安全的引用的时候,可以主动把这些不安全的东西屏蔽掉。
- 可以通过服务端响应头限制,也可以使用 meta 标签在前端进行限制。
- report-uri 只能通过响应头设置,meta 设置无效
限制方式
default-src 限制全局、connect-src、img-src、manifest-src、style-src、script-src、frame-src、media-src、font-src...
response.writeHead(200, {
'Content-Type': 'text/html',
// 只能通过 http 的方式加载,此时 inline script 无法加载
'Content-Srcurity-Policy': 'default-src http: https:',
});
response.writeHead(200, {
'Content-Type': 'text/html',
// 不能引入外链的脚本,只能使用本域下的 script
'Content-Srcurity-Policy': "default-src 'self'",
});
response.writeHead(200, {
'Content-Type': 'text/html',
// 不能引入外链的脚本,允许特定域名内的数据加载
'Content-Srcurity-Policy': "default-src 'self' https://source.com/",
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
限制页面内表单的提交
在返回包含 form 的 HTML 页面数据时,在响应头添加 CSP 的限制。
response.writeHead(200, {
'Content-Type': 'text/html',
// 表单只能提交到当前域
'Content-Srcurity-Policy': "default-src 'self';form-action 'self'",
});
2
3
4
5
report uri
在遇到限制之后可以向 /report 地址发送一个 csp-report 的报告
✅ Content-Srcurity-Policy-Report-Only 会做识别限制进行上报,仍然会加载数据
response.writeHead(200, {
'Content-Type': 'text/html',
'Content-Srcurity-Policy': "img-src 'self'; report-uri /report",
});
2
3
4
Meta 设置 CSP
限制所有
<meta
http-equiv="Content-Security-Policy"
content="default-src 'self' form-action 'self'"
/>
2
3
4
限制 ajax 请求
response.writeHead(200, {
'Content-Type': 'text/html',
'Content-Srcurity-Policy': "connect-src 'self'",
});
2
3
4
或
<meta
http-equiv="Content-Security-Policy"
content="connect 'self'"
/>
2
3
4